Page List: All the Cool Ebook Developers Are Doing It
Page List — an ebooks’s cross-reference to the print edition’s pagination — is an EPUB3 standard, but it’s a bear to implement coming from an InDesign workflow.
Laura Brady (@LauraB7) of Brady Type introduces a time-saving pair of scripts from Kris Coppieters, genius of InDesign scripting.
One of the great benefits of EPUB3 is the ability to create ebooks with many layers of rich navigation. From InDesign you can create a full set of landmarks for a robust EPUB3 file. But compiling a Page List has been, up until now, a fairly onerous task.
Kris Coppieters from Rorohiko has come to our rescue, ebook developers. He is part wizard, I am convinced. He has written two scripts. The first one is called Page Staker. When you run it, it will put a text box on the paste board at the top left of each page in an InDesign document, overlapping by one pixel into the page area, with a live page number in it. The folio will have a unique paragraph style assigned to it, and the frame that it is in will have a distinct object style as well. The frame will be anchored to the start of the page’s content within the HTML.
When the file is exported to EPUB, you get some HTML markup that looks like this:
<div id=”_idContainer000″ class=”com-rorohiko-pagestaker-textframestyle”>
<p class=”com-rorohiko-pagestaker-paragraphstyle”>1</p>
</div>
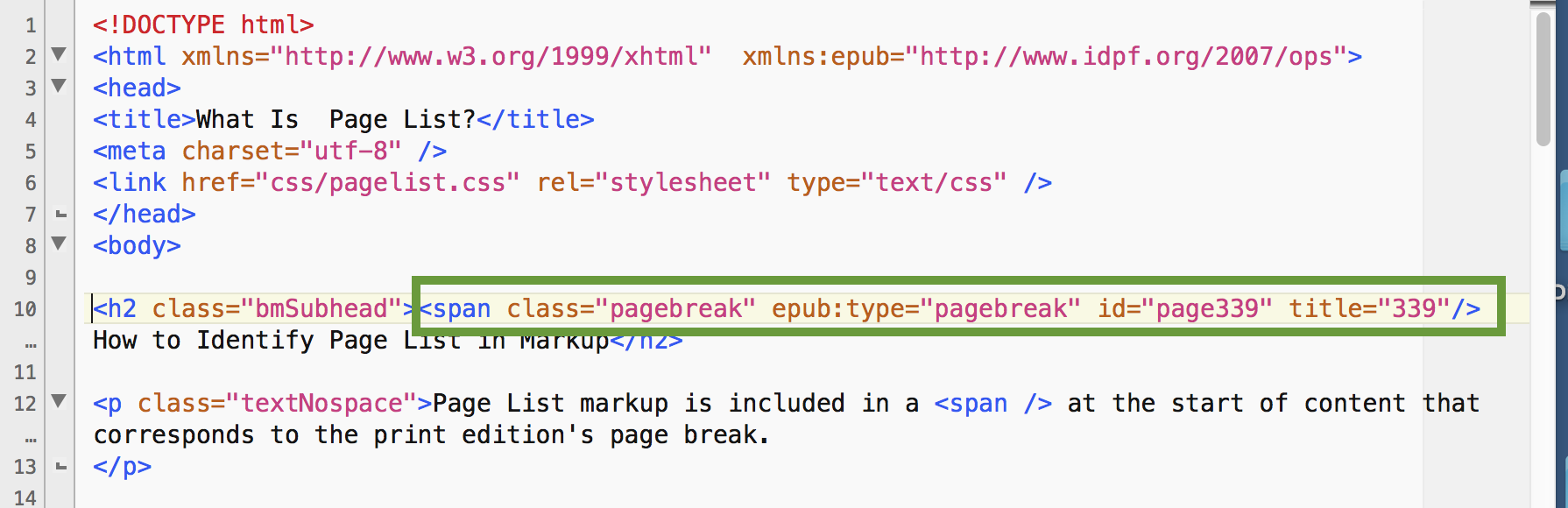
The second script, EPUBOgrify, uses regular expressions to turn that into this:
<span epub:type=”pagebreak” id=”page1″ title=”1″ />
Let’s take a second here to reflect on the work saved. Page Staker will put a live folio on the page – something we used to have to got through several steps to do: make the folio live on the page from the master page, use a script or re-key the folio to make it live, move the frame off the page if necessary, and then anchor it at the start of the page. This quick script does all of that.
Converting the resulting HTML markup into something manageable has been a mind-bending exercise up to now. Well, for me, anyway, as RegEx is not one of my special skills. It would take me ages to get the find-and-replace string exactly right, and to get it working across all the HTML documents in an EPUB. (Stop laughing, RegEx people.)
The epub:type semantic inflection applied at the print-page level marks the print-page break in the HTML. It is required of any EPUB3-compliant book but, I suspect, has been reserved for special-use cases up until now.
The second script, EPUBOgrify, also compiles a text document with the start of the book’s Page List for use in the toc.xhtml. The Page List is reliable but comes out not in order because the file names don’t sort quite right. That’s easy to straighten out before pasting into your toc.xhtml.
There are several wonderful things about these scripts:
- They are going to save the average ebook developer about four hours per book.
- They are going to save us from a very tedious four hours of work.
- If you are like me and don’t have mad RegEx skills, these are a lifesaver.
- They are going to help us all make better, more robust and accessible EPUB3 books.
Kris at Rorohiko is a top-shelf scripter so these scripts are neither free nor cheap. But if you are interested in fully-compliant EPUB3 with rich navigation, I think you’ll find them worth the cost.
Each script is US$50, or US$75 for both. I am going to handle selling these so navigate over to this link for further detail.
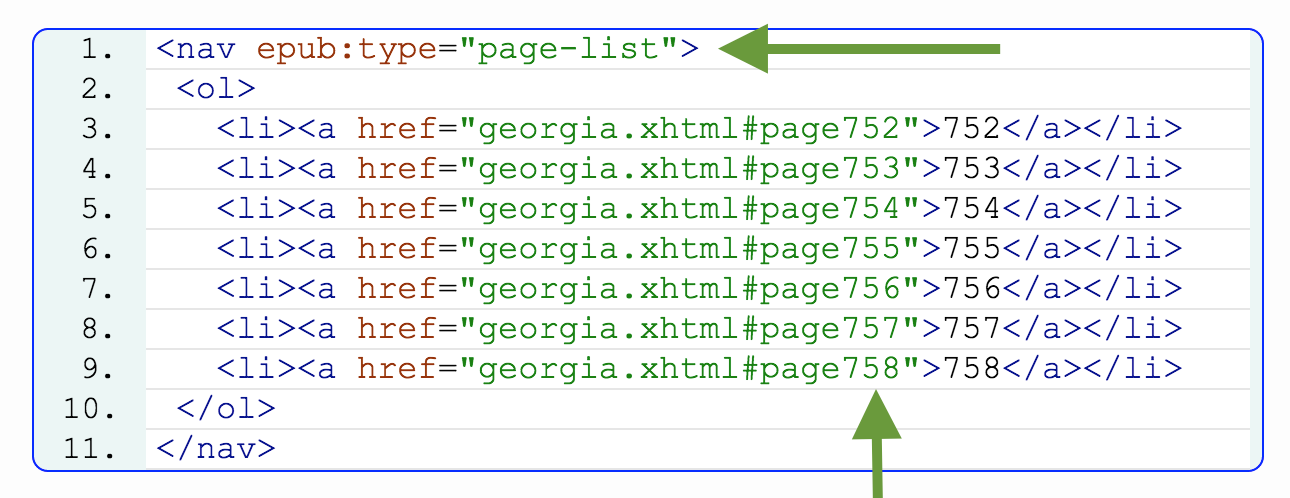
From the Editor: for reference, here’s the IDPF’s sample of how Page List is incorporated into the toc.xhtml:
Tell me, as I am new to this. Is the Page List and epub:type feature mandatory or optional for EPUB3 documents? Thanks in advance.
Hello Mary, these EPUB3 features are not required for a valid EPUB, but inclusion creates a richer document.
[…] more: Laura Brady this week published a piece here on epubsecrets.com about two new scripts for creating Page List within […]
I just got both these scripts, and I can already see that these script will save me A LOT of time. Before now I didn’t give much thought to adding page numbers to the ebooks I was developing, the time spent to do it by hand (either in InDesign or in HTML) wasn’t worth it to me, but now with these scripts there’s no reason or excuse NOT to add page numbers to any ebook I develop. Thank you Kris and Laura for developing these scripts!