DropToScript

This article is by Matthew C.C. Chan is an ebook developer and currently the Cross-Media Assistant at House of Anansi Press/Groundwood Books in Toronto. His work involves turning typeset manuscripts into elegant, accessible ebooks for a variety of reading platforms. Interests include publishing workflow, automated production, and code.
The scripts referenced in this post can be downloaded here:
https://github.com/BCLibCoop/nnels-a11y-publishing/tree/master/DropScripts
Using simple PHP scripts to build a better workflow
If you’re a professional working in ebook production, chances are that you’ve spent some time thinking about “workflow”, that alchemical process by which your precious working hours and your tools are combined to produce elegant, accessible ebooks.
If you’ve come upon your current workflow organically (i.e. by adding little things to your process as you discover that they’re necessary), you’ve probably also come to the conclusion that you spend a non-trivial amount of those precious working hours performing the same simple modifications to each ebook that comes across your desk.
The fact is, all workflows are not made equally – and a workflow which is more constrained on working hours can be remade to be more technology or tool driven. Enter DropToScript.
More information about publishing workflows
If you’re interested in learning more about the state of the art in modern publishing workflow design, a great place to start is the Book Industry Study Group’s recent recommendations: https://www.youtube.com/watch?v=-SY20SXFLq4
About the developers
DropToScript is the product of a collaboration between leading book industry professionals and software-engineer Kris Coppieters (@zwettemaan and kris@rorohiko.com). Kris is also the developer of other eproduction tools such as PageStaker and EPUBOgrify.
This project was undertaken by NNELS (National Network of Equitable Library Service) and was made possible thanks in part to support from the Government of Canada’s Social Development and Partnership Program – Disability Component (SDPP-D).
What is DropToScript?
DropToScript is an app designed to be used by eproduction professionals to automate certain tasks involved in refactoring an EPUB – or in lay terms, it takes care of the step in the ebook production process where you take a skeleton EPUB and perform the host of simple modifications to it that bring it up to your standards for finished product.
The app automates these simple modifications by running a variety of built-in PHP scripts on a given EPUB. Once the app is properly setup and configured, all a user has to do is interface with the app via an intuitive drag-and-drop interface.
What is PHP?
PHP is a scripting language originally designed to assist web developers. But since the major components of an EPUB are xHTML and CSS, ebook developers can use PHP too!
But what if I don’t know PHP? Can I still use DropToScript?
Yes! DropToScript’s built-in script templates were designed with exactly you in mind. All you need is a basic understanding of regular expression patterns and the app will do the rest.
Depending on your specific workflow, you might use DropToScript to automate:
- Converting page breaks in your xHTML into a
pagelist navelement - Replacing junk placeholder
<title>element content with actual meaningful titles - Removing unnecessary classes from xHTML elements
- Streamlining CSS stylesheets by removing redundant styling rules
More generally, DropToScript is designed to be user-customizable, and can easily be tweaked to automate any refactoring task that can be summarized as a global regular expression find-and-replace operation.
Help me clean up my Adobe InDesign EPUB!
DropToScript is ideal for use in post-processing the procedurally generated EPUBs outputted in Adobe InDesign-based print-first workflows. The app is compatible with any W3C EPUB standard-compliant EPUB – but it was designed with cleaning up InDesign EPUBs as a specific use case.
But I already use Rorohiko PageStaker/EPUBOgrify. Do I need DropToScript?
EPUBOgrify is a nifty little piece of tech, and there’s no reason why you need to stop using it if it satisfies all your ebook production needs. But users familiar with EPUBOgrify will see that DropToScript is functionally a superset of the capabilities of EPUBOgrify – yes, it can be used in conjunction with PageStaker to create full featured pagelist nav elements, but it can be customized to do much, much more besides.
This how-to guide will get you started using DropToScript by providing step-by-step instructions and examples. Let’s get started.
Installing DropToScript
The remainder of this guide includes examples using DropToScript v1.0.11_1.0.20 (the most recent release as of the writing of this guide).
IMPORTANT!
Follow each step in this part of the guide closely. The examples in the rest of this guide will not work unless the app and its dependencies are initially setup correctly.
Once you’ve downloaded DropToScript.1.0.11_1.0.20.zip, unzip the archive onto your computer wherever you want to store the app.
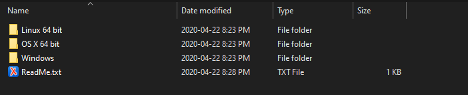
Though the unzipped archive will contain Linux, MacOS, and Windows versions of DropToScript, you will only use the files inside the directory which pertains to your specific operating system.
Once the app has been unzipped. Do not alter its file structure. The app will not function if the executable file (i.e. the .exe, .app, or Linux executable) is separated from its associated subfolders (i.e. ./DropScripts and ./DropToScript Libs).
Installation: For MacOS Users

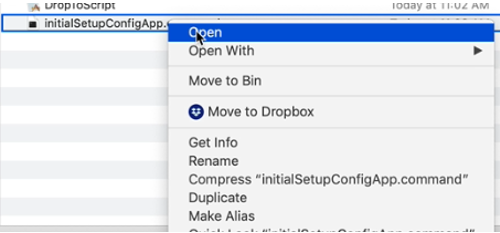
OS X 64 bit/DropToScript directory. MacOS users must de-quarantine the application before MacOS will allow the app to access its own scripts.Inside the OS X 64 bit/DropToScript directory, locate and control-click or right click on ![]() . From the context menu which appears, select “Open”.
. From the context menu which appears, select “Open”.
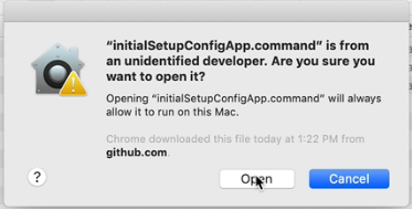
At the security prompt, again select “Open”.
This should open an instance of Terminal and execute the commands required to de-quarantine the app.
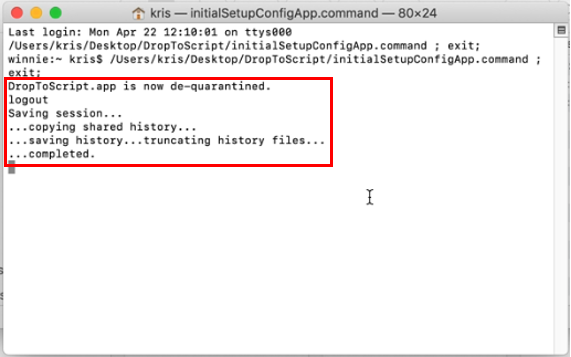
The Terminal can now be closed. Done! DropToScript is now ready to be used!
Next we’ll go through a similar installation process, but for users on a Windows operating system.
Installation: For Windows Users
Installing PHP for Windows
Under the hood, DropToScript relies on a PHP interpreter to process the app’s PHP scripts. Windows does not come pre-installed with a PHP interpreter, so you’ll have to install one if you haven’t already.
In your web browser, open https://www.php.net/downloads and click through the “Windows Downloads” link under the heading “Current Stable PHP”.
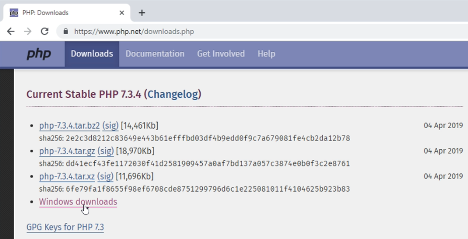
On the next page, select the link to download the “Thread Safe” zip of PHP that is appropriate for your version of Windows.
For most users, this will be “VC15 x64 Thread Safe”.
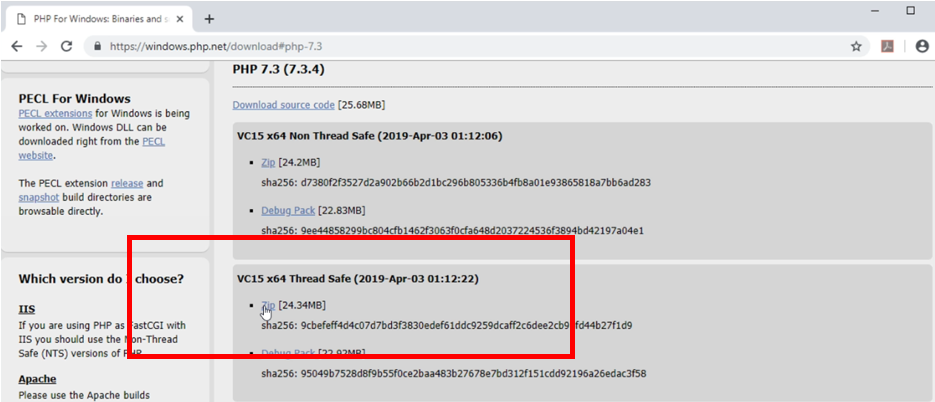
Save the zip somewhere on your computer.
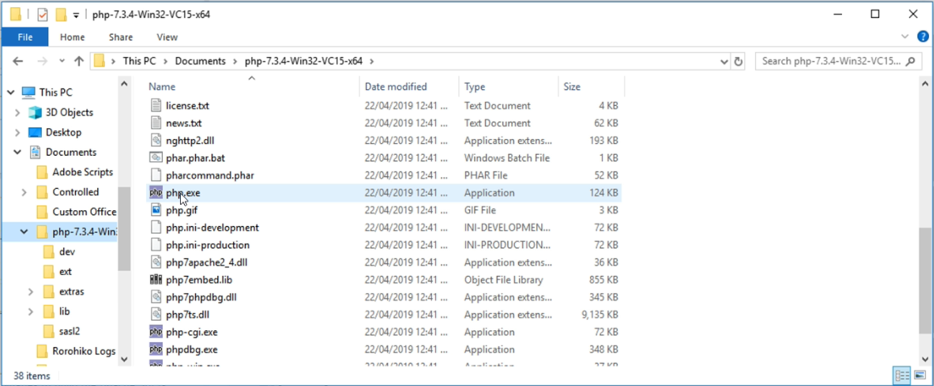
Then unzip the archive into a directory where you want to store the PHP interpreter. Inside this directory you will see an executable called ![]() . Keep the path of this executable in mind, as it will be important later.
. Keep the path of this executable in mind, as it will be important later.
Okay. Next we’ll have to make sure the DropToScript app knows where to find the PHP interpreter.
Users who want the option of running DropToScript’s built-in PHP scripts directly from Windows’ command line will additionally have to set the Path variable in windows to point to the directory containing this PHP interpreter. Doing so is completely optional, and not a prerequisite for using DropToScript’s default drag-and-drop interface.
Setting Up DropToScript for Windows
Navigate back to the unzipped DropToScript folder, and open the Windows directory. Inside this folder, open the DropToScript directory.

Windows/DropToScript directory.In this folder, open ![]() .
.
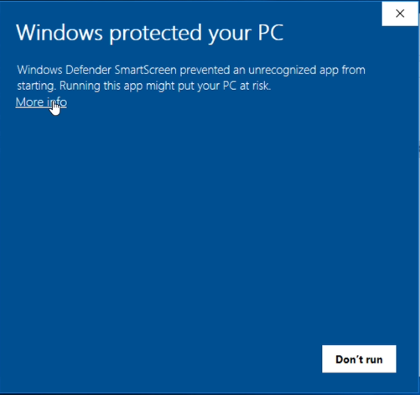
If a Windows security dialogue box appears, select the “More info” link, followed by “Run anyway”.
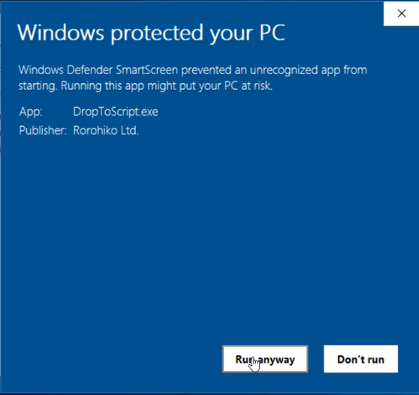
After ![]() opens, you should see DropToScript’s Preferences window:
opens, you should see DropToScript’s Preferences window:
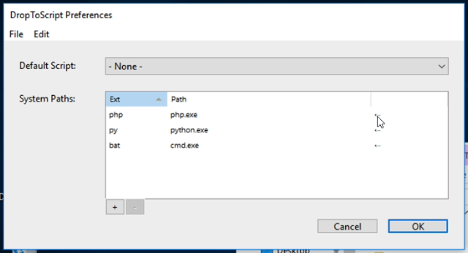
Click on the tiny arrow in the row labelled “php”, and in the file browser which opens, find and select ![]() . Then click “Open”.
. Then click “Open”.
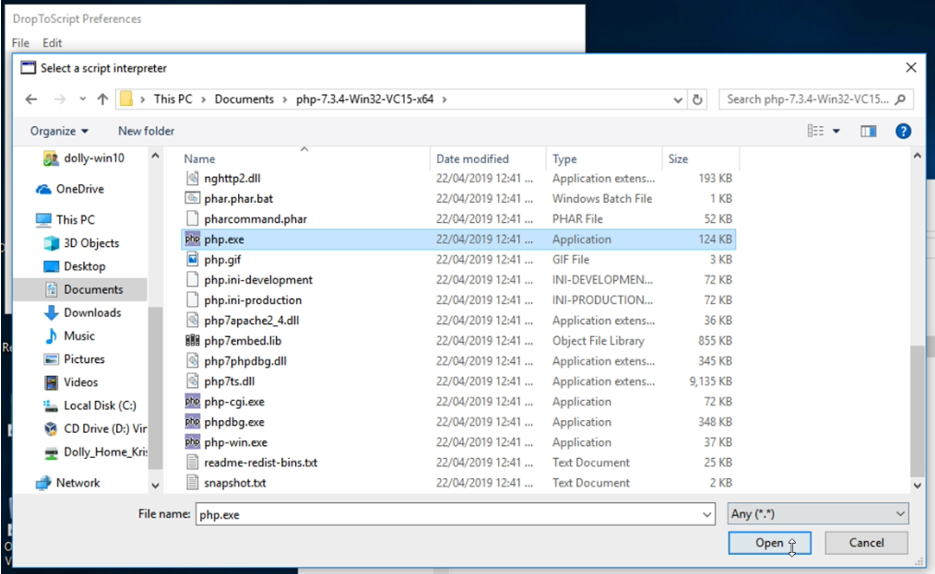
Recall that in this example we unzipped the PHP interpreter into the user’s Documents directory. So in DropToScript’s Preferences window, we navigate back to this directory, open the folder containing the PHP interpreter, and select php.exe within.
Back in DropToScript’s Preferences window, click “OK” in the bottom right corner. Done! DropToScript is now ready to be used!
Note: The Windows version of DropToScript also relies on Microsoft’s Visual C++. If a recent version of the Visual C++ redistributable is not already installed (e.g. on certain older versions of Windows), users will also have to download and install the version of vc_redist.xxx.exe appropriate to their version of Windows before using DropToScript. More details on this step can be found here.
Using DropToScript
The DropToScript app comes packaged with 7 built-in user configurable script templates. Each script template can be run separately from the others, and when used in conjunction, have the potential to significantly reduce the time required to finish an EPUB and ready it for distribution.
As mentioned above, each script template is user configurable – the exact behaviour of each script, when run on a given EPUB, is determined ahead of time by the contents of a configuration file.
Note: To keep scripts and their associated configuration files organized, all script templates and configuration files follow a simple naming convention – if the actual script is called script.php, then the associated configuration file will be called script.config.txt.
The built-in script templates and a set of default (i.e. unmodified) configuration files will all be found in the DropScripts folder, located inside your DropToScript directory.
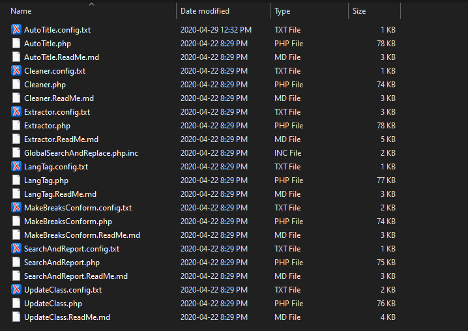
DropToScript/DropScripts directory. Note the file structure of the various scripts (each ending in the .php file extension) and their associated configuration files (each ending in the .config.txt file extension).A Note on “Global’ vs. “Project-Specific” Configuration Files
Users of DropToScript may choose to save their customized configuration files in either of two locations:
- In the same parent directory where their work-in-progress EPUB is being stored; or
- In the
DropToScript/DropScriptsdirectory (i.e. overwriting the default configuration files).
When a script template is run on a given EPUB, DropToScript will first look for a version of the script’s associated configuration file in the same parent directory as the EPUB (i.e. in the first location). Only if no associated configuration file is found in this location will DropToScript proceed to look for a configuration file in DropToScript/DropScripts (i.e. the second location).
In practice, this means that users can setup project-specific configuration files to be saved alongside their EPUB projects, while saving a more general, project-agnostic version of their configuration files (i.e. a “global” configuration) in DropToScript/DropScripts.
For a given EPUB, if the global configuration will suffice, DropToScript can be run “as-is” (i.e. without any modification of configuration files). But if the global configuration will not work for the given EPUB, the user simply needs to create a set of modified configuration files in the EPUB’s parent directory.
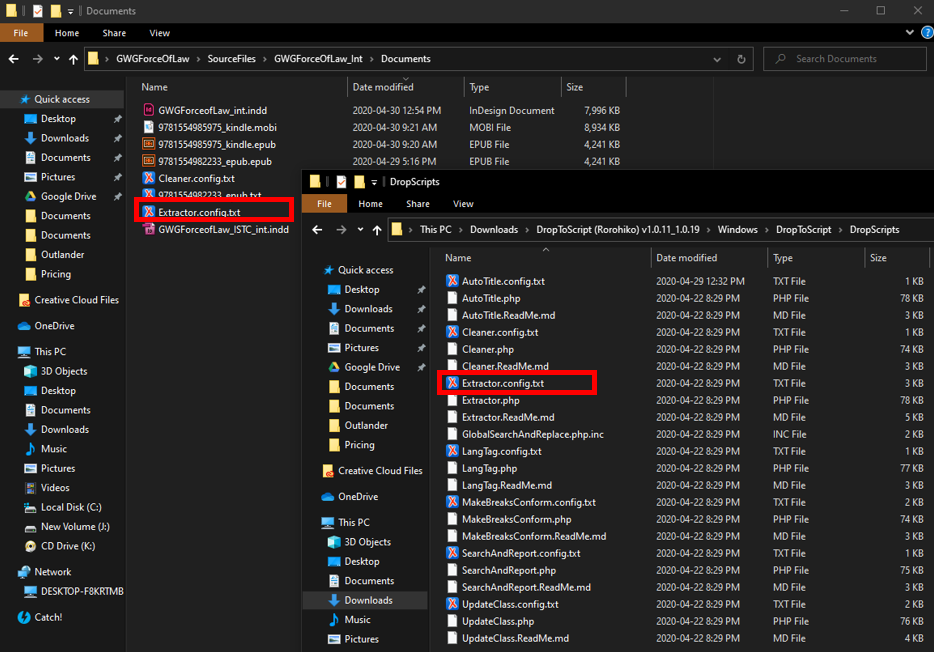
An example of two valid locations for configuration files. When Extractor.php is run on ![]() DropToScript will automatically modify the behaviour of the script based on the contents of the version of
DropToScript will automatically modify the behaviour of the script based on the contents of the version of Extractor.config.txt located alongside the EPUB (i.e. the version of the configuration file in the top-left window of the example). If this version of Extractor.config.txt did not exist, DropToScript would default to the global settings found in DropToScript/DropScripts (i.e. the version of the configuration file in the bottom-right window of the example).
Okay. Now that you understand how to configure DropToScript’s scripts, let’s look at what each built-in script template does and experiment with building our own custom configuration files. For the remainder of this guide, let’s use this xHTML file with this linked CSS file.
What if I want to run the same script on every file in an EPUB instead of on individual files? You can absolutely do that! In the following examples we’ll run the scripts on individual files as a way of keeping things simple, but DropToScript can process groups of files and even entire EPUBs the exact same way. When groups of files or an entire EPUB is used as input, DropToScript will run a chosen script against each file.
AutoTitle
Let’s begin with AutoTitle, a little script that solves a narrow but annoying problem. When Adobe InDesign layouts are saved as EPUBs, InDesign has no way of discerning what content a particular file in the EPUB will contain. It therefore gives every generated xHTML file a <title> element that just contains its own file name – not very helpful.
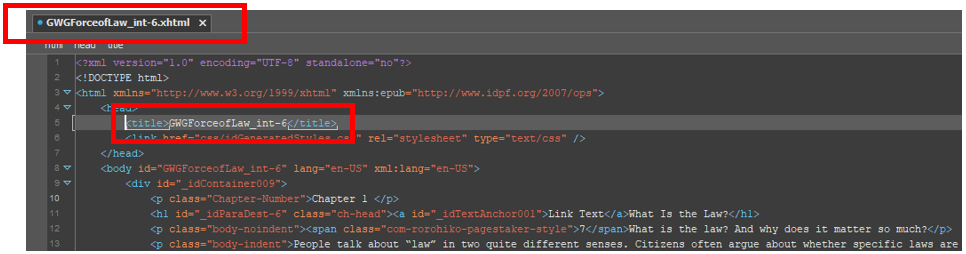
<title> tag.The solution to this problem is to replace the default content of the <title> tag with something more meaningful – say, the same content that, in properly semantic HTML, would be contained in a heading tag.
AutoTitle adapts this heuristic and applies it to a given input file. Specifically:
- The script will automatically replace the content of the
<title>tag with the content of the first<h1>tag. - But if the file contains no
<h1>tag then the script will attempt to look for the content of the first instance of each successively lower level of heading tag (i.e.<h2>, then<h3>, etc.). - If the file contains no heading tags, the script will instead substitute the content of the first
<p>tag. - And if the file contains no heading tags or
<p>tags, it will do nothing.
Let’s try running the script on our example xHTML file to observe the result.
Locate the example xHTML file and drop it onto the DropToScript app.
DropToScript’s Script Selection window will appear. From the dropdown box, select AutoTitle.php and push “OK” in the lower right corner. For now, close the Completion Report window which appears. (We’ll return to this window later, for a different script.)
In the parent directory of the example xHTML file, you should see that a new file with the .old extension has been generated. This is DropToScript’s automatic backup of your input file.

Now let’s re-open the example xHTML file and see what the script did.
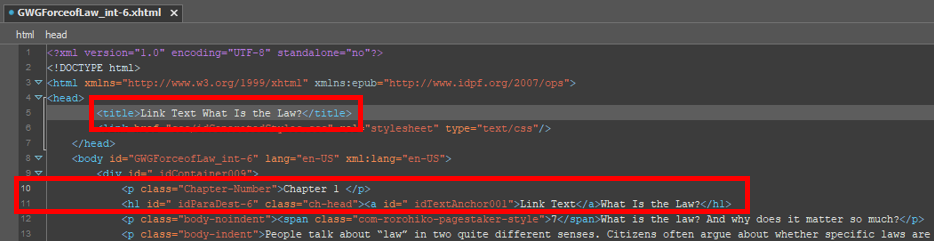
AutoTitle replaced the old content of the <title> tag with the content of the first <h1> tag!
Also, notice that even though our <h1> tag wasn’t the first bit of text content in the file, AutoTitle skipped the <p> tag containing the text “Chapter 1” and went straight for the content of the <h1> tag. As mentioned above, AutoTitle would only have used the content of that opening <p> tag if it had searched the example xHTML file and found no heading tags at all.
But there’s a problem: The content of our first <h1> tag wasn’t just text. It also contained an anchor tag, which itself contained more text. (This sometimes happens when, for example, you tell InDesign to link to your <h1> text from elsewhere in the document.) When AutoTitle copied the content of the <h1> tag it copied the text content out of all the nested elements as well.
We probably didn’t want this, so let’s try creating a custom configuration file for AutoTitle and re-running the script.
First let’s delete the modified file and restore the original xHTML example file by changing the extension of the automatic backup file from .old back to .xhtml. Now let’s navigate to where the global configuration files are stored (i.e. the DropToScript/DropScripts directory) and make a copy of AutoTitle.config.txt into the same parent directory as our example xHTML file. Great! This copy is our project-specific configuration file for AutoTitle.

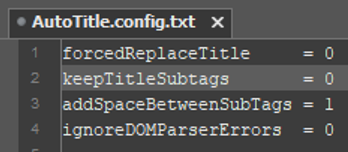
Now let’s open the copied configuration file and examine some of AutoTitle’s settings.
forcedReplaceTitle– When this option is set to1AutoTitle will replace every<title>tag it comes across. When set to0it will instead replace a<title>tag only if the name of the inputted file (excluding its file extension) is the same as the content of the<title>tag that would be replaced.
In practice, this forces AutoTitle to look for the junk placeholder<title>tags created by InDesign. It also means that you can manually edit some of the<title>tags of an EPUB and then run AutoTitle after without worrying that the script will override your changes. Let’s try changing this setting to0for now.
keepTitleSubtagsandaddSpaceBetweenSubTags– WhenkeepTitleSubtagsis set to1, AutoTitle will concatenate all text found within whatever tag its logic tells it to copy from. But if it is set to0AutoTitle will instead ignore all sub-elements within the tag selected by its logic. And as we saw from the earlier example, whenaddSpaceBetweenSubTagsis set to1, AutoTitle will insert spaces between the text that it concatenates when deciding what text to replace the<title>tag with. Setting it to0turns this behaviour off. IfkeepTitleSubtagsis set to0, this setting has no effect either way.
Let’s try changing keepTitleSubtags to 0 and saving our changes to the configuration file.
Aside: Recall that since we are making these customizations to a project-specific configuration file, these settings will DropToScript/DropScripts.
Now that we’ve customized AutoTitle’s configuration file, let’s try running AutoTitle again to see what happens. (Again, drag the example file onto DropToScript and select AutoTitle from the menu. When the script is finished, open the modified xHTML file.)
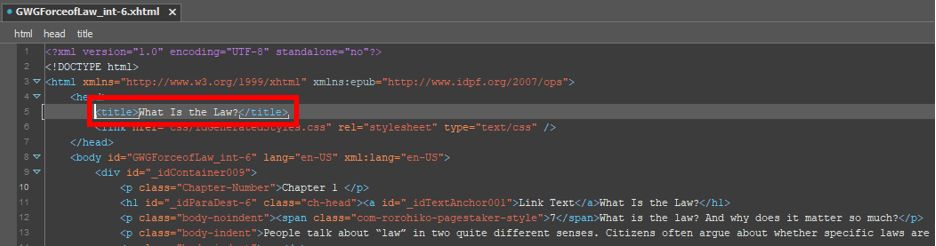
Notice how AutoTitle has once again replaced our <title> tag with the content of our first <h1> tag. But because we modified the keepTitleSubtags setting our configuration file, this time the script has stripped out the content of all sub-elements.
Next, let’s look at a script template designed to take care of another common issue – misplaced lang attributes.
LangTag
Consider our example xHTML file:
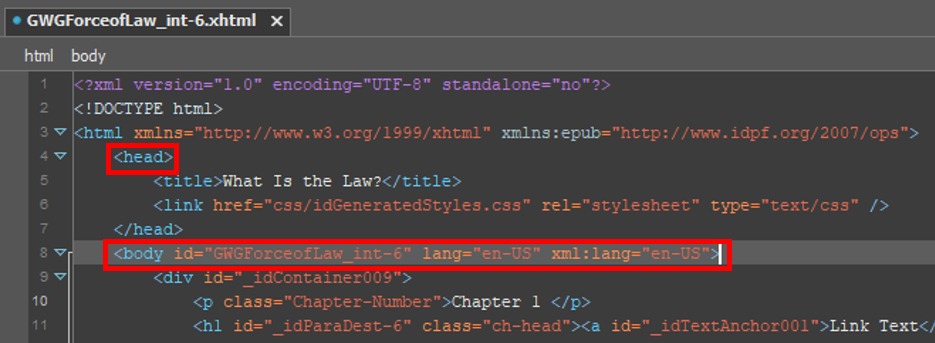
A cursory inspection reveals that lang attributes describe the body element as being written in English, but that the language of our head element has been left undeclared. eBook developers familiar with Adobe InDesign generated EPUBs will recognize this missing lang attribute in the head as a minor, but persistent, error. As both the body and head of this document are written in English, best practice would actually have us move the lang attribute from the body element into the html element. Fortunately, this is what LangTag was designed to accomplish.
Let’s try running LangTag on our example xHTML. When the script finishes, navigate back to the xHTML example file’s parent directory.
Note that a new file has been created. When you ran LangTag, DropToScript created an automatic backup of the example xHTML file and tried to append the .old file extension. But because the directory already contained a file with that name, DropToScript backed up the example xHTML file by appending _2.old instead. You can think of this as version 2 of the backup.
A note about DropToScript’s automatic backup feature: In fact, DropToScript will automatically increment the backup number, up to a maximum of 5, each time it is run on a file located in a parent directory already containing old backups. If DropToScript is run again after the version 5 backup has been created, the next backup it creates will overwrite version 2. In this way the original backup with the .old file extension is never accidentally overwritten.
Note also that if executing a particular script does not result in any modification to the input file, DropToScript will not create an automatic backup.
Now open the modified example xHTML file.

The lang attributes have been moved up to the html element, exactly as we wanted.
Though the default behaviour of this script should cover the vast majority of cases, here are a few notes on settings in LangTag’s configuration file (i.e. LangTag.config.txt):
attrsToMove– This setting controls which attributes the script will attempt to promote from the body element to the html element. As you saw from the example, by default the script will look forlangandxml:langattributes.defaultIfMissing– What if, for whatever reason, nolangattribute is found in the body at all? In that case, the script will createlangattributes and supply them with the value given todefaultIfMissing. If this setting is not changed, the script will supply a default value ofen.
Next, let’s examine one of DropToScript’s most useful and versatile script templates – Cleaner.
Cleaner
Called simply Cleaner, the purpose of this script is as pure as its name would suggest: Given an input file of the correct file type, the script will apply any number of user-defined regular expression search patterns to the file contents, replacing any matches with a corresponding user-defined replacement pattern.
By chaining sequences of these regular expression search and replace operations, users are able to tailor this script to automate a variety of refactoring tasks – even where those tasks may be highly specific to your own workflows.
As an example, let’s create a project-specific configuration file to experiment with by copying Cleaner.config.txt from DropToScript/DropScripts into the parent directory of our example files. Open this copy, and let’s take a look at the contents.
Within this file, any line beginning with # is a comment line (and will be ignored when the script runs). From the comments, we may get a sense of the purpose of Cleaner’s global configuration: It normalizes the document type declaration and html element of input files by swapping any existing version of those elements with the standardized versions in the replacement pattern at line 22.
But let’s say normalizing files in this way isn’t a necessary part of your workflow (as, for example, is the case if you work with EPUBs generated by Adobe InDesign). In that case, you can build a simpler configuration file which does only what you require the script to do.
In this case, our example xHTML file contains a number of placeholder span elements that we have to properly convert into pagebreaks before the EPUB is finished. Let’s see if we can customize Cleaner to do this for us.
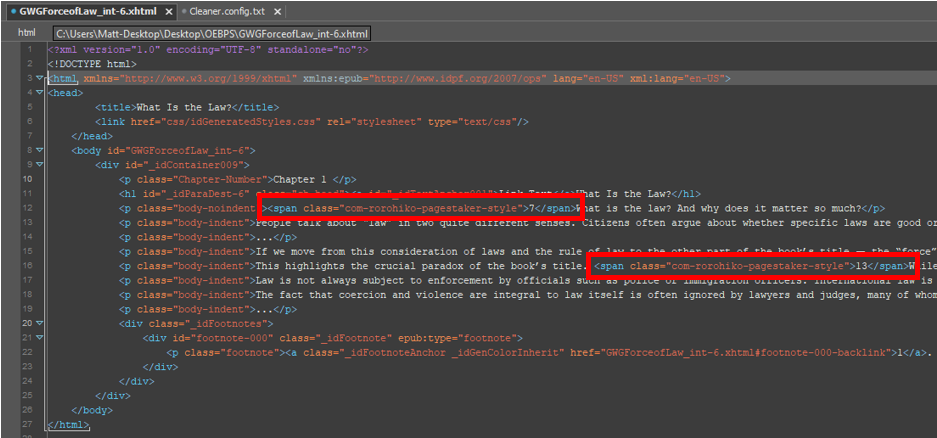
Let’s start by deleting everything from line 5 to the end of the file and starting over (almost) from scratch.
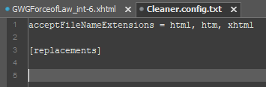
So that the configuration file is easy to modify and maintain in the future, each search and replace pattern should begin with a concise description of the operation. Let’s save this in a comment.
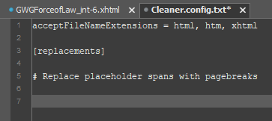
Now we have to build our first search and replace operation. As you may have noticed in the global configuration file, each operation has 4 operative parts: a search pattern, a replacement pattern, a delimiter that marks the end of the operation, and, optionally, a flag that tells the script how you’ve encoded newlines in the replacement pattern.
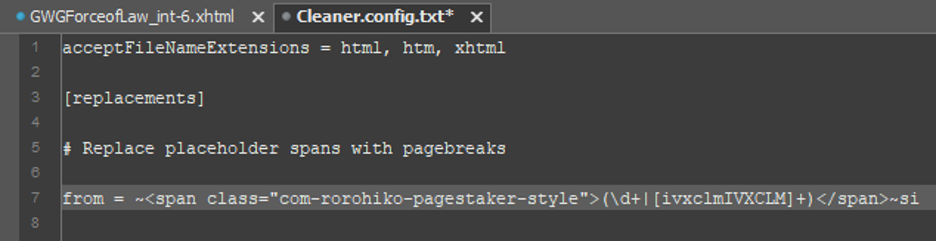
Let’s start by making a search pattern. Each search pattern starts with the symbol from = (i.e. the word from, followed by a space character and an equals sign). After this, provide a search string in Pearl Compatible Regular Expression (PCRE) format.
IMPORTANT! Cleaner will not recognize any search strings other than PCREs. For detailed documentation on PCREs please consult: https://www.php.net/manual/en/reference.pcre.pattern.syntax.php
Since we know that we’re looking for some sort of placeholder span that contains a page number as the content, let’s try something like:
Okay. On the next line of the configuration file, we need a replacement pattern. Each replacement pattern starts with the symbol to = (i.e. the word to, followed by a space character and an equals sign). After this, provide a replacement string.
In our example, since we want to replace our matches with pagebreaks, we should use something like:
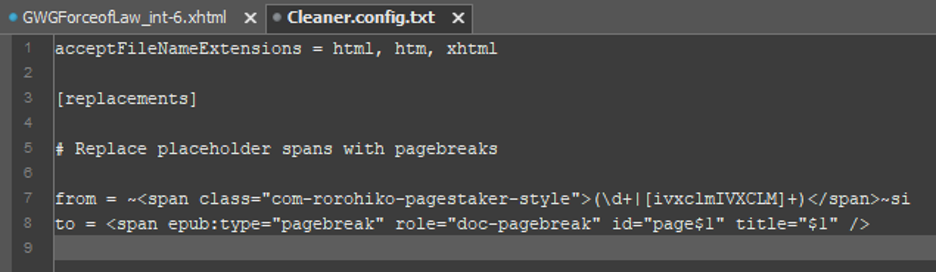
Note how the $1 symbol is used to refer back to the capture group in the search pattern. In replacement strings, the symbol $1 represents the value of the first capture group of each match, $2 represents the value of the second capture group, etc.
Finally, don’t forget to end each search and replace operation with the end of operation delimiter ++ (i.e. a new line containing just two plus signs).
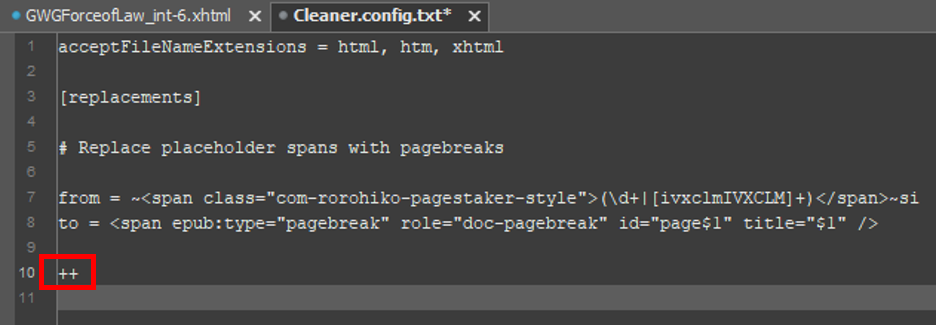
Now let’s run Cleaner on our example xHTML file and observe the result:
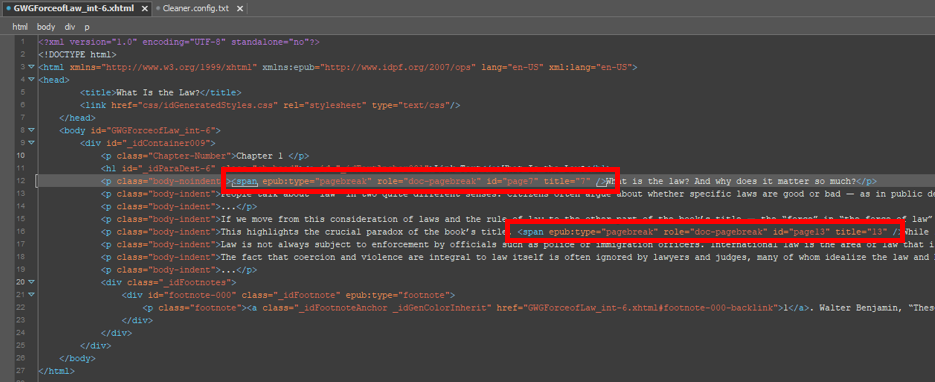
Fantastic! But what about that footnote? Won’t the missing aria-role attribute get flagged as a violation of accessibility standards? Let’s fix that with another custom search and replace operation. Maybe something like:
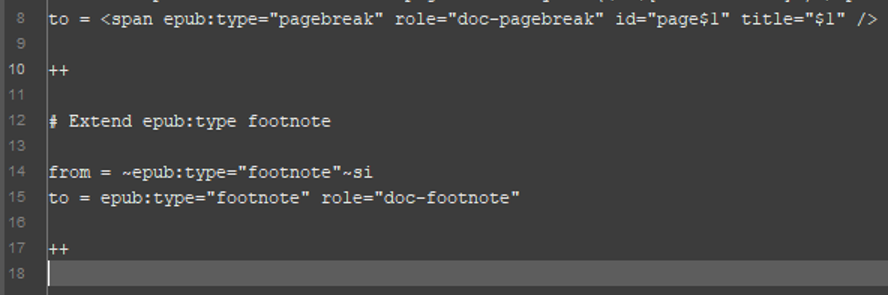
If multiple search and replace operations are found in the same configuration file (and properly delimited), Cleaner will run each operation in sequence until it gets to the end of the configuration file.

But please note the following critical rules about replacement strings:
- Most non-printing characters cannot be represented by their encoded equivalents. For example, to include a tab character in a replacement string, type a literal tab (i.e. a blank space will appear in the replacement string) instead of
\t - The exception to the above rule about encoding characters is the newline character, which must be encoded if used in the replacement string – typically as
\n. However, if an encoded newline appears in the replacement string, the line immediately after the replacement pattern must be a properly formattedto_encodedNewLinesflag. - If the replacement string includes leading whitespace (e.g. the replacement pattern is intended to be an indented line of xHTML), then the entire replacement string must be enclosed in a set of double quote marks
The following example search and replace operation, excerpted from the project-specific configuration file of a different ebook project, shows these replacement string rules in action:

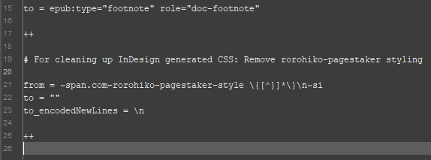
The operation searches for the opening tag of the div element that contains the img element referencing the EPUB’s cover image. When a match is found, the replacement pattern swaps in two properly indented replacement lines of xHTML. In the replacement string, note that the indentations are created by actual tabs instead of encoded tab characters, and that because the replacement string begins with a tab, the entire string is wrapped in double quotes. Also note that because the replacement string inserts two lines of xHTML, a \n is used to encode the newline character. The to_encodedNewLines flag then appears on the line after the replacement pattern, declaring \n as the symbol used to encode the newline character.
Next, take a look at the example CSS file, starting at line 134. Now that we’ve replaced all our placeholder spans, we don’t really need the rule that previously styled them.
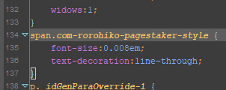
So let’s just construct a search and replace operation in Cleaner’s configuration file to take care of this for us:
But if you try to drop the example CSS file onto DropToScript and select Cleaner, you’ll find that nothing happens. Why? This is because by default Cleaner is configured to ignore all files with extensions other than html, htm, and xhtml.
To modify this behaviour, refer to the setting acceptFileNameExtensions on the very first line of the configuration file. This is a comma-separated list of the file extensions on which Cleaner will run. To allow Cleaner to modify our example CSS file, simply add css to the list.

In this way, you may also customize Cleaner to be able to operate on your opf files, xml files, svg files etc.
In fact, the general principle of expressing repetitive refactoring tasks as sequences of search and replace operations is so versatile that two of DropToScript’s other script templates, MakeBreaksConform and UpdateClass, can really be thought of as customized configurations of Cleaner.
MakeBreaksConform
This is a script which attempts to locate elements that serve as placeholders for pagebreaks, and replaces matches with actual, properly formatted pagebreaks. In order for the script to work, however, the placeholder elements must:
- Be anchor tags or
spantags, - Which are either empty, or self-closing, and
- Have an id attribute matching one of the following specific patterns:
id="page-PAGENR"
id="page_PAGENR"
id="page PAGENR"
id="pagePAGENR"
where PAGENR is any page number. If all these conditions apply, the script will replace each placeholder element with a pagebreak of the form:
<span epub:type="pagebreak" id="ID" role="doc-pagebreak" aria-label="PAGENR" />
If these conditions do not apply to pagebreak placeholders in your specific workflow, the same effect can be achieved using Cleaner configured with a custom configuration file (see example in section on Cleaner).
UpdateClass
This script is intended to assist ebook developers specifically with the task of refactoring class attributes. Using an elementary form of conditional logic, the script will:
- Isolate all elements of an input file with a type matching a given search pattern, then
- Within this subset of elements, apply a search pattern against each
classattribute, and - If a match is found, apply a replacement pattern against the matched class
The default global configuration file for UpdateClass is setup to remove certain default classes assigned by Adobe InDesign (e.g. _idGenCharOverride, _idGenParaOverride) from any element. However, UpdateClass’s conditional logic is such that this configuration could easily be modified, for example, to apply only to certain types of elements, or to swap the default class, if found, to a different class.
Note however that although both Cleaner and UpdateClass perform global search and replace operations on input files, the configuration file for UpdateClass does not follow the same structure as the configuration file for Cleaner.
Rather, the configuration file for UpdateClass is structured as a modified JSON file, containing a top level list called processTags. Each entry within this list contains 2 key-value pairs:
tagMatch– A search pattern representing the subset of elements within which you would like to search for classes to modify, andprocessClasses– Which is itself a list, where each list entry is defined as 2 key-value pairs:classMatch– A search pattern you wish to apply against each class attribute found within the subset of elements defined bytagMatch, and
classReplace– A replacement pattern to apply when the corresponding search pattern finds a match.
IMPORTANT! Because the configuration file for UpdateClass is structured as a modified JSON file, all search and replacement patterns must be enclosed in double quotes (per the JSON file format specification). As a result, all double quotes within a search pattern or replacement pattern must be escaped with a \ (i.e. must be immediately preceded by a backslash).
This rule applies in addition to the rules for escaping special characters which would otherwise apply to PCRE patterns. Failing to escape characters in this way will break this script.
Finally, let’s take a look at the last category of script templates, starting with Extractor.
Extractor
What if your refactoring task requires you to search for content in a given file and, instead of replacing found matches “in-place”, pull the matches for processing in a different file? A common use case for this sort of behaviour is gathering up all the pagebreaks in a file to make a pagelist nav element. For such a task, Cleaner wouldn’t work – you’d want to use Extractor instead.
An example will make this more clear. Let’s try to find all the pagebreaks in our example xHTML and format them as a list of links that can readily be pasted into a pagelist nav.
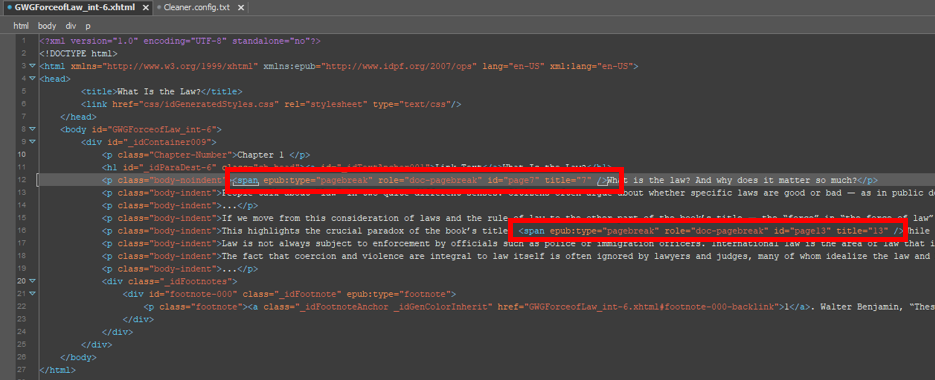
pagelist.Create a project-specific configuration file for Extractor by copying Extractor.config.txt from DropToScript/DropScripts into the parent directory of our example files. Then open the copy.
The default global configuration file is designed to look for placeholder pagebreak elements matching any of 4 different pre-defined document structures – but none of these document structures match our example xHTML file. Instead, let’s try customizing our own configuration file.
Start by deleting everything from line 7 to the end of the file. Then, below the line containing the symbol [extractions], add a short descriptive comment about what we’re trying to do.
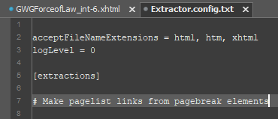
Then, on a subsequent line, write the search pattern that Extractor should look for inside our example xHTML file. This line will be in a format that is similar to, but not the same as, a search pattern for Cleaner’s configuration file. Each search pattern for Extractor also begins with the symbol from = (i.e. the word from, followed by a space character and an equals sign), but note that the search string which follows this symbol is not a strict PCRE. Specifically, this search string differs from a search string that would be valid in Cleaner’s configuration file in the following ways:
- The search string should not be surrounded by delimiters, and
- Pattern modifiers cannot be used
The search patterns in Extractor are always case sensitive.
Something like the following should work:
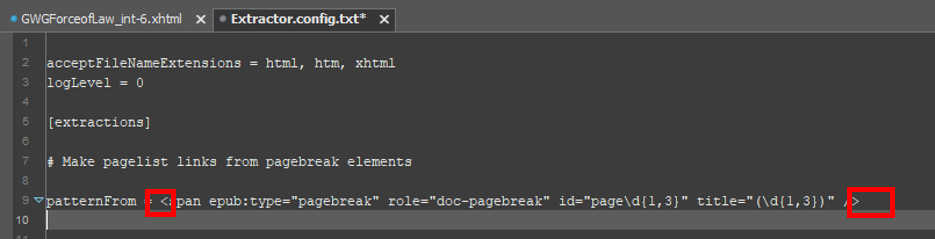
On the following line, write your replacement pattern. Again, note that a replacement pattern for Extractor’s configuration file is similar to, but not the same as, a replacement pattern for Cleaner’s configuration file. Each replacement pattern for Extractor also begins with the symbol to = (i.e. the word to, followed by a space character and an equals sign), but the replacement string that follows differs in the following ways:
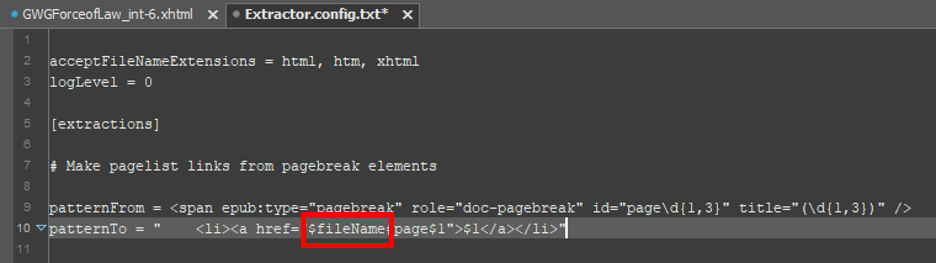
- In addition to using symbols of the form
$1to refer back to the values of capture groups, the symbol$fileNamecan be used to represent the name of the input file in which a given match is located, and - The symbol for the newline character in a replacement string is always
\n. This does not need to be declared anywhere in the configuration file.
In all other respects the replacement string should be formatted the same as replacement strings in the configuration file for Cleaner.
For our example, we’ll want to transform the page number from our matches into an anchor tag with a valid href attribute. We’ll probably also want to wrap the anchor tag in a li element and indent it so that it’s ready to be pasted directly into a pagelist nav. Let’s try something like:
$fileName symbol, which is specific to Extractor.When Extractor is run, DropToScript will create a new empty file in the parent directory of the input file on which the script was run. Upon finding a match, the corresponding replacement pattern will be applied, and the result of this replacement will be appended to a line at the end of the newly created file.
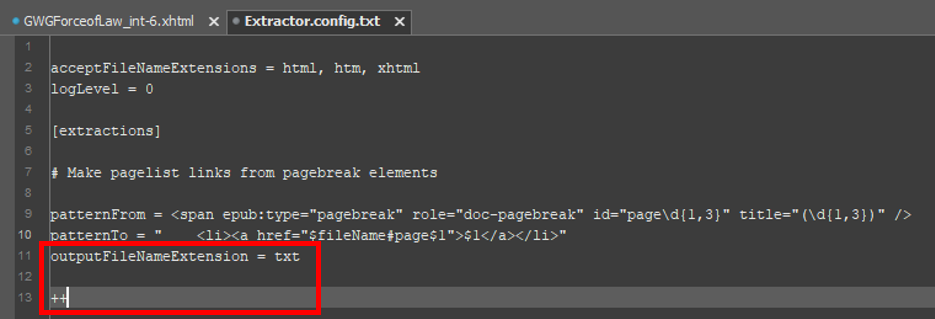
On the line immediately after the replacement pattern, add the setting outputFileNameExtension = txt. The newly created file will always have the same name as the input file, but with the outputFileNameExtension setting you can specify the file extension that Extractor will apply to the new file. (The .txt extension is fine for our example.)
Finally, as in Cleaner’s configuration file, end the Extractor operation with the end of operation delimiter ++ (i.e. a new line containing just two plus signs).
Great! Now save your customized configuration file and run Extractor to observe the results.
First, notice that no automatic backup of the input file is created. In fact, Extractor never creates an automatic backup because the input file is never directly modified. Instead, DropToScript has created a new .txt file. Let’s open this file and take a look at our results.

Perfect! For each pagebreak in the example xHTML file, we now have a corresponding link that is ready to be pasted into a pagelist nav element.
SearchAndReport
This script template is really just a variation on the functionality of Extractor. SearchAndReport is designed to look for a search pattern within a given input file, and then apply another search pattern to each of the matches of the initial search (allowing users to isolate certain substrings of the initial matches). A replacement pattern is then applied to the matches of this secondary search. However, instead of being saved to a new file, SearchAndReport simply prints the results in the Completion Report window that appears after a script is run.
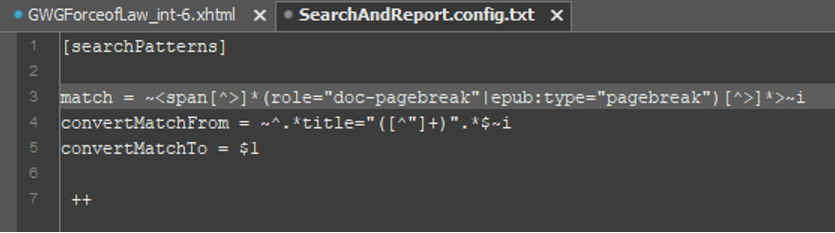
As an example, running SearchAndReport on our example xHTML file using this configuration file (a modification of the settings we used earlier in our Extractor configuration file):
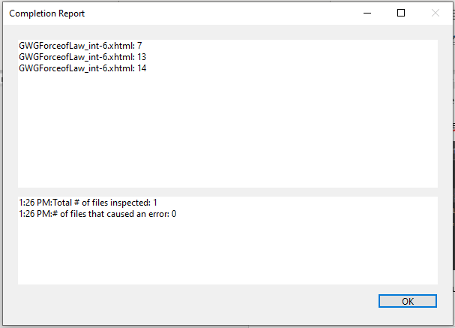
Results in the following output being printed to the Completion Report window when SearchAndReport is finished executing:
In Summary
Just as there is no single, optimal publishing workflow that is equally applicable to all circumstances, no single tool is going to be a “silver bullet” that automatically transforms the way you develop ebooks. However, with the versatility and customizability of the suite of PHP scripts built into DropToScript – when paired with an ebook developer possessing the aptitude and ingenuity to deploy them creatively – you can certainly go a long way.
Links
Links go here. i.e. Wherever you want readers to go next in order to:
- Download DropToScript
- Learn about Rorohiko
- More about pagelist, document title, clean HTML and other ebook accessibility principles on the Daisy Knowledge Base