Generating image descriptions for ebooks with machine learning tools

This is a guest post from Daniella Levy-Pinto, a Toronto-based expert in accessibility, including digital technology and livable spaces. She works to promote and inform a paradigm shift towards born-accessible-content and inclusive design. She is on Twitter @DaniellaLevyP and she can also be reached at daniella@levy-pinto.ca.
Image descriptions are essential elements of accessible ebooks to ensure that blind readers and readers with other print disabilities can access the same information available to all other readers. Creating meaningful image descriptions, however, requires an understanding of the image, and can also be time-consuming. This post explores the potential use of machine learning tools, specifically object and scene recognition services, via an Application Programming Interface (API) to generate descriptions that a publisher can use as initial drafts of the description of the relevant images. It describes the basic process of tagging images using machine learning and presents information on various commercial image recognition services.
The potential use of machine learning tools… via an Application Programming Interface (API) to generate descriptions that a publisher can use as initial drafts of the description of the relevant images
Why and how to describe images
Images that are not merely decorative add to the content of books, and require a description to make that content accessible to readers with print disabilities such as blindness or low vision. When images are not described via alternative text (sometimes called alt-text), their content is entirely unavailable to anyone reading the ebook in non-traditional ways. Even if an image comes with a caption, this is usually not enough information; alt text will enrich the experience for readers with print disabilities, and help increase reading comprehension by providing all aspects of the book to everyone.
Alt text will enrich the experience for readers with print disabilities, and help increase reading comprehension by providing all aspects of the book to everyone.
Writing textual image descriptions for books is time-consuming: it is necessary to figure out which images need a description, then identify the most relevant aspects to describe (this step generally requires understanding the context by reading the contiguous text), and craft the descriptive text. Image descriptions are typically embedded in alt-tags of EPUB files, or they are included in a separate section within the book in the case of complex images. Depending on the publisher’s workflow, image descriptions can be added to an ebook at different stages of the production process. Some publishers require authors to provide text for image descriptions to ensure descriptions are meaningful and relevant. In many cases, however, this may not be possible, and editorial or production staff in-house may need to undertake the creation of image descriptions for new titles. Adding image descriptions can be time-consuming and also requires some learning.
The process will still require human intervention to enhance, edit, and correct the draft descriptions for the foreseeable future.
Several Machine Learning (ML) tools use computer vision to identify and tag thousands of images. The use of some of these tools is promising for ebook developers and other content creators, as they help automate at least some steps in the creation of image descriptions. The process will still require human intervention to enhance, edit, and correct the draft descriptions for the foreseeable future.
Publishers working to improve the accessibility of their ebooks are likely to require image descriptions for one of the following: 1) current/future titles, to ensure all images in current/future titles have descriptions at the time of production, for born accessible ebooks; and 2) ebook remediation, which requires adding image descriptions to ebooks in a publishers’ backlist. Using machine learning tools to automatically generate image descriptions can potentially reduce the time needed to remediate new and backlist titles.
Using automation to describe images
Describing an image involves generating a human-readable textual description. This process requires understanding the content of an image and translating it into a natural language. The solution requires that the content of the image be understood and translated to meaning in terms of words. Of course, the words must string together comprehensibly. Automated solutions such as those presented below, combine both computer vision and natural language processing.
The process of recognizing images and generating automatic descriptions uses an ML model called convolutional neural networks (CNN) to identify and tag objects in images. A deep convolutional neural network is used as the feature extraction submodel. This network can be trained directly on the images in the image captioning dataset. Alternately, a pre-trained model can be utilized, or a hybrid model where a model that has been pre-trained on a generic dataset is used as a base and later fine-tuned with more specific examples relevant to the book’s context. Most tools allow the user to select pre-trained models, or to create a custom model.
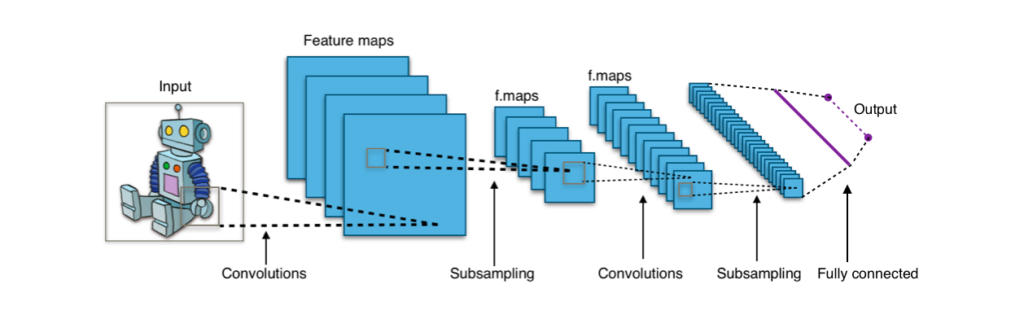
For object recognition, a neural network processes the pixels that make up an image. The neural networks are presented with numerous samples of images with objects that have been previously identified by a human. The network learns from the samples to recognize objects with similar characteristics. For instance, a tool is shown thousands of images of shoes, and the model (a neural network, for example) would extract the main features or characteristics that images of shoes have. If the model is presented with an image of an elephant, it would not find the features of shoe images and will not be able to confidently identify the elephant. To enhance this model it should also be trained with thousands of labelled images of elephants from which it can learn.
For object recognition, a neural network processes the pixels that make up an image. The neural networks are presented with numerous samples of images with objects that have been previously identified by a human.
Scene recognition describes the actions that may be occurring on a scene of a video or frame, through a combination of CNN for object recognition first, with recurrent neural networks, to produce a textual description based on the image.
Commercial tools
There are several tools on the market for using machine learning to automate the tagging of images. Tech giants like Amazon and Google, as well as startups like CloudSight and Clarifai are offering image recognition services. These tools can sort through countless images and quickly return data. The tools below can recognize, analyze, and interpret images, and allow the processing of thousands of images per month. The words or sentences they return can be used to craft draft image descriptions for adding them to ebooks. Although the technology is not perfect and a human will still need to edit them, this technology has the potential to facilitate the creation of alt-text.
Setup
Most image recognition tools come with an API key that lets users call the API by creating a REST call. An API is a set of rules that allow programs to talk to each other. When users make a request to the API by linking to a specific URL, they get a response, a piece of data back (called a resource). Requests can be sent to an API using various programming languages such as Java, Python, Node, etc. For example, it is possible to write descriptions for images with CloudSight and Python. CloudSight offers a Python library; once installed, the user selects an image and sets up the basic imports, before making the actual API call. In Python, first, the user can authenticate using their API key. The next step is to open the image file and make the request itself to the server. The final step is to print out the response, and CloudSight will return an object with the response data.
CloudSight
CloudSight appears to be the tool that could potentially be most useful for publishers to aid in generating descriptions for images on backlist titles, as it is highly accurate with image and scene recognition. The quality of descriptions is excellent; while other services return keywords to classify an image, CloudSight can return sentences and phrases with a high degree of detail. The TapTapSee app is a well-known product from this company that provides automated image descriptions for blind and visually impaired people using a smartphone.
While other services return keywords to classify an image, CloudSight can return sentences and phrases with a high degree of detail.
It goes beyond the objects and categories by providing context and scene descriptions of images or videos. It comprehends visual content and forms a human-like descriptive sentence by choosing each word in the phrase from a flexible vocabulary of over 20,000 words. Users can choose from a network that focuses on the primary subject of an image (CloudSight-primary-subject), or from their other network (CloudSight-whole-scene) that focuses on the entire scene of the image.
Let’s see a description generated by CloudSight. Go to the CloudSight website with a trial account, and click on “Try It Now” to upload your images. The tool will return image descriptions.

CloudSight Generated the following description: “man in black leather jacket and black cap” which is quite helpful, but could be more specific, for example: “Young light-skinned man wearing a waist-length black motorcycle jacket with epaulettes, standing on a staircase facing a railing with his hands in his pockets and looking slightly off to the side” provides more information and ensures that those who cannot see the image know what kind of jacket and cap the young man is wearing.
Cloudsight offers different subscriptions to accommodate users’ needs; they don’t quote generic pricing, it all depends on your projected volume, use case, and any extra training required. The company likes to have hands-on collaboration with potential new clients, especially during early testing. CloudSight provides API access and a certain number of free API calls for testing.
One of the most interesting and potentially useful aspects of this service is that it combines machines + humans with CloudSight’s Hybrid solution. The unique technology allows for real time responses while also helping the tool learn and improve over time. If the output from the general model is not perfect, it is also possible to work with the team to tailor it to your specific use case. It may be possible to work with them on bringing humans partially into the loop to handle processing historical images, for example; likely the pricing will be higher than a pure AI solution, but the results will also be more specific and potentially useful.
Google’s CloudVision API
Google’s CloudVision API is close to a plug-and-play image recognition API. It’s pre-configured to tackle the most common image recognition tasks, like object recognition or detecting explicit content. It takes advantage of Google’s extensive data and machine-learning libraries, making it ideal for detecting landmarks and identifying objects in images, some of the most common uses for the CloudVision API.
The API provides a set of features for analyzing images (including text and document text detection, object localization, face, landmark, and logo detection). It can access image information in different ways: it can return image descriptions, entity identification, and matching images; It can identify the predominant colour from an image.
One of the most promising features of this tool is its OCR capability: it can detect printed and handwritten text from an image, PDF, or TIFF file. Text detection performs Optical Character Recognition (OCR) on text within the image. Text detection is optimized for areas of sparse text within a larger image. For example, an illustration may contain a street sign or house number. This feature could be useful for images with text that was set as images. Document text detection performs OCR on dense text images, such as documents (PDF/TIFF), and images with handwriting.
Pricing is tiered: the first 1000 units used each month are free; units 1001 to 5,000,000 cost $1.50. Pay only for what you use, charges are incurred per image. For files with multiple pages, such as PDF files, each page is treated as an individual image. Each feature applied to an image is a billable unit.
Clarifai
Clarifai is an out-of-the-box image recognition API. It can tag, organize, and understand images and video using artificial intelligence and machine learning. Accessible via Cloud API integration secure On-Premise service. Offers a free API which lets users plug in any image data. Predict uses AI to identify objects in the images, videos or text it is given. It can be used for Automated Image & Video Tagging, as well as OCR
It offers two different types of models: 1) machine learning models that learn patterns and produce different outputs based on these patterns; 2) fixed function models that produce outputs based on a predetermined set of parameters. These models can be combined into distinct workflows. Calling the Predict API means asking it to predict the likelihood that the data contains a given concept. Each model can recognize a finite number of concepts. Creating a custom model means teaching the model to recognize new concepts. Models include:
- Detection model: Locates the people, places and things within images, videos, and live feeds. Detection takes the classification technology further by identifying the exact placement of concepts within an image or video.
- The ‘General’ model recognizes over 11,000 different concepts including objects, themes, moods, and more; this model is an all-purpose solution for most visual recognition needs.
It offers 5,000 free operations per month; month to month usage.
Amazon Rekognition
Amazon Rekognition analyzes still images, and can also provide insight into videos. It’s capable of: detecting object, scene, and activities (e.g. playing football); facial analysis (e.g. smiling, eyes open, glasses, beard, gender); detecting and recognizing text in images (e.g. street names, captions). It can recognize and extract textual content from images with support for most fonts, including highly stylized ones. It detects text and numbers in different orientations, such as those commonly found in banners and posters.
There are no minimum fees in place for this service, pay only for data you use approach; does not require long-term contracts or complex licensing. The cost is comparable to Google Vision.
Computer Vision – Microsoft Azure
Computer Vision – Microsoft Azure analyzes content in images by extracting rich information from images.
The cloud-based Computer Vision API provides access to advanced algorithms for processing images and returning information. By uploading an image or specifying an image URL, Microsoft Computer Vision algorithms can analyze visual content in different ways based on inputs and user choices. Uses visual data processing to: label content, from objects to concepts, extract printed and handwritten text, and recognize familiar subjects like brands and landmarks. Try it
Final thoughts
One of the most important criteria for an image recognition solution is its accuracy, i.e. how well it identifies images. CloudSight and Google’s CloudVision appear to be the most promising tools to generate alt-text to describe images in backlist titles. To the best of my knowledge, CloudSight is the only solution that generates sentences to describe objects and scenes. Experimenting with some of the tools mentioned in this post to generate draft descriptions that will be the base for useful alt-text for images in backlist titles may be a good way to use the large numbers of requests per month that these services offer.
While at present, machine learning tools still generate incomplete/inaccurate descriptions that need to be verified by a human and corrected, as the technology continues to evolve, descriptions will be more accurate and require less editing. No image recognition tool is perfect. Producers will still need to manually check images and edit descriptions, to ensure they are accurate and that the language matches the content and the intended audience. If part of the process is automated, the time needed to do this may be reduced, because producers will not need to start from scratch.